
Die Beobachtung und Analyse von strategischen Entwicklungen im Umfeld der Technologiebasis von Produkten und Dienstleistungen eines Unternehmens ist in einer globalisierten Wirtschaft ein wettbewerbsentscheidender Erfolgsfaktor. Herkömmliche Tools zur Unterstützung dieser Aufgabe, wie das Technologieroadmapping oder Technologieradare, werden meist durch eine redaktionelle Aufbereitung marktrelevanter Datenquellen erstellt und gepflegt. Dies ist bei der sich rasch beschleunigenden, global verteilten F&E-Landschaft mit immer kürzeren Entwicklungszyklen, sowie der daraus resultierenden steigenden Daten- und Informationsmenge nur mit großem Ressourcenaufwand leistbar.
Ziel des Projekts Text2Tech ist die Erforschung und Entwicklung automatisierter Methoden zur Informationsextraktion aus unstrukturierten Textquellen, um Unternehmen entscheidungsrelevantes Wissen über Technologieentwicklungen rasch und effizient zur Verfügung stellen zu können. KI-basierte Verfahren zur Informationsextraktion (IE) ermöglichen es bereits jetzt, ausgewählte Informationen, z. B. zu Personen, Firmen und Orten automatisiert aus Textquellen zu gewinnen. Im Projekt Text2Tech sollen solche Ansätze weiterentwickelt werden, um maschinenlesbares Wissen über Technologien, Technologiekategorien, Firmen und ihren Beziehungen untereinander, aus deutsch- und englischsprachigen, domänenspezifischen Textquellen zu extrahieren, exemplarisch am Beispiel der Automobilbranche. Die wichtigsten Forschungsziele sind die Modellierung und “Befüllung” von domänenspezifischen Wissensgraphen (Knowledge Base Population), die Entwicklung von Verfahren zur cross-lingualen Eigennamenerkennung und Verlinkung (Named Entity Recognition bzw. Entity Linking), Relationsextraktion (Relation Extraction), sowie die Entwicklung von Modellkompressionsverfahren, sodass Modelle auch auf “kleiner” Hardware effizient laufen.
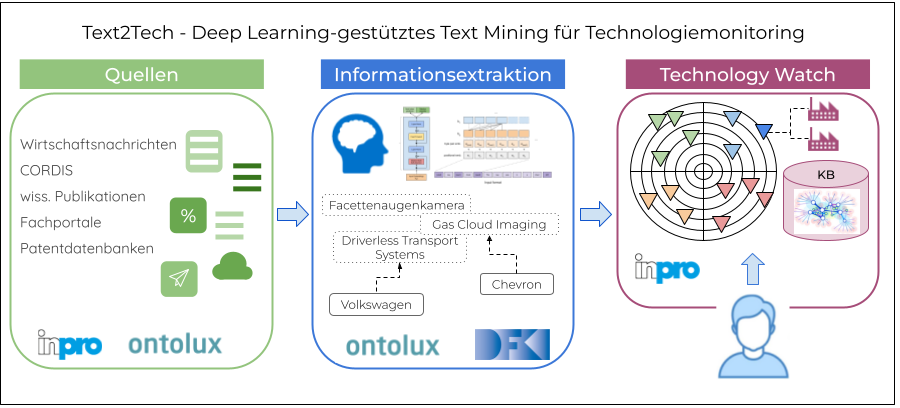
Das Projekt Text2Tech ist zum 1. Mai 2022 gestartet, und läuft bis zum 30. April 2025. Konsortialführer ist die Firma Neofonie GmbH / Ontolux, Projektpartner die inpro GmbH und das Speech & Language Technology Lab des DFKI. Text2Tech ist Teil des Technologieprogramms „Erforschung, Entwicklung und Nutzung von Methoden der Künstlichen Intelligenz in KMU (KI4KMU)“, und wird vom Bundesministerium für Bildung und Forschung (BMBF) unter dem Förderkennzeichen 01IS22017B gefördert.